
Kafka is a middle-ware application developed by Apache Foundation, used for building real-time data pipelines and streaming apps, which is scalable and has fault-tolerant capabilities.
Posted below are the basic terminologies used by Kafka, and a simple diagram explaining the process:
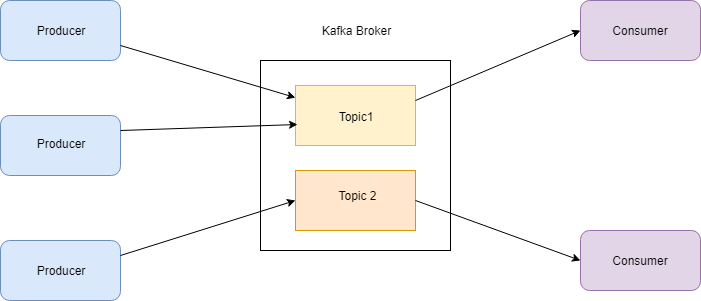
Producer: A application that sends messages to KAFKA
Message: A small peice of data, a simple array of bites. Each row in a file can be send as a message.
Consumer: A application that reads data from KAFKA
Kafka Server: Received messages from Producer, and gives it to Consumer.
Kafka Broker: A Kafka Server that stand as a middle man to exchange messages.
Kafka Cluster: A group of Kafka Brokers that works in a distributed environment to get the job done.
Topic: Arbitrary name given to a data set so that consumers can as for the correct data from the Broker. Similarly when producer sends a message to Kafka, it needs to be send to specific Topic.
Partition: Break up of topics to smaller chunks. The number of partitions for each topic is decided by the person who created the partition.
Offset: A sequence ID assigned to messages that arrives in a partition. Message IDs start from 0.
A message’s full address: A unique combination of Topic name – Partition number – Offset ID.
Consumer Group: It is a group of consumers working as it clustered to one.
Scaling Kafka: Kafka cluster, partitioning and consumer group is a the path to take.
Kafka do not allow more than 2 consumers to access a single partition.